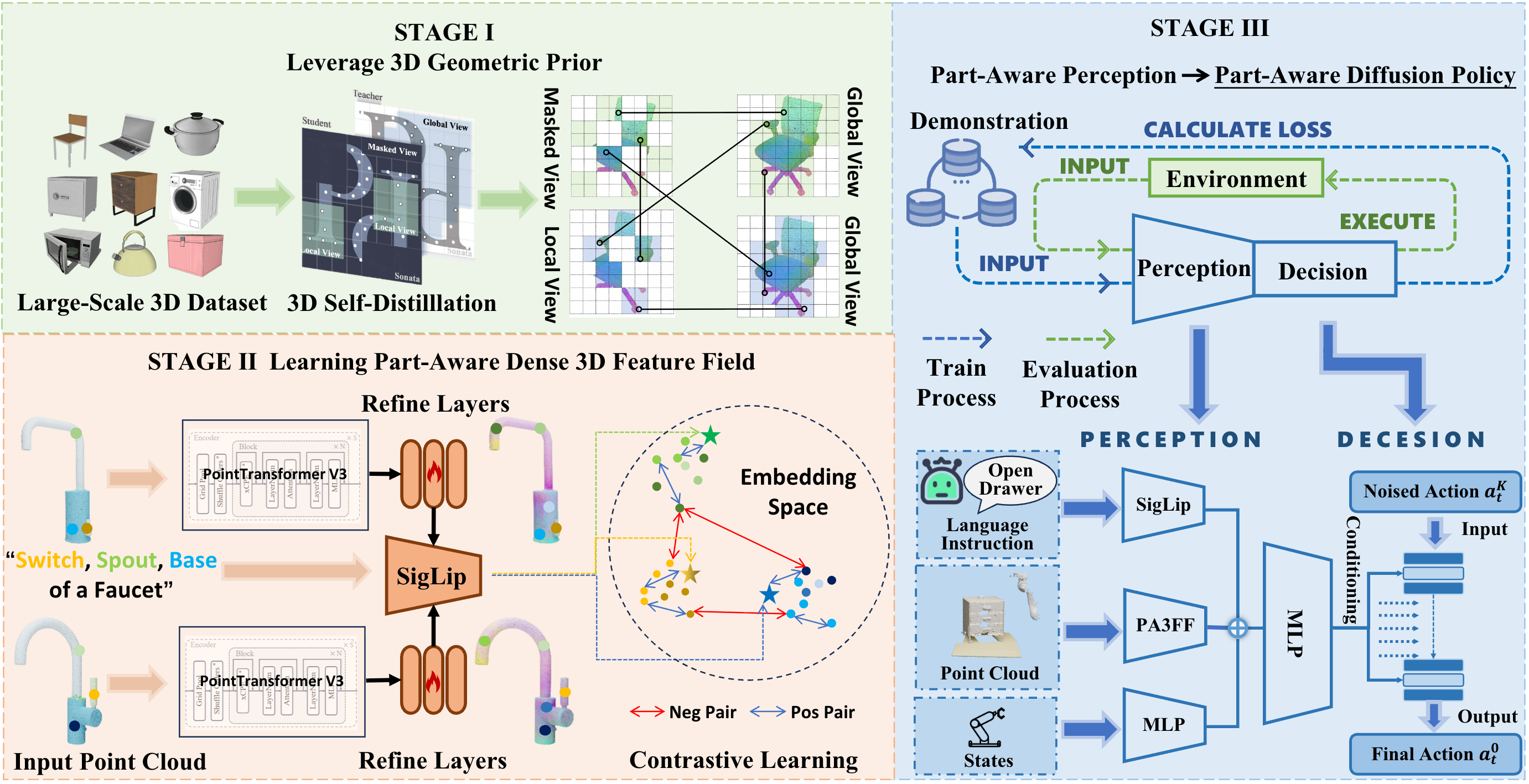
Overview
Key Contributions:
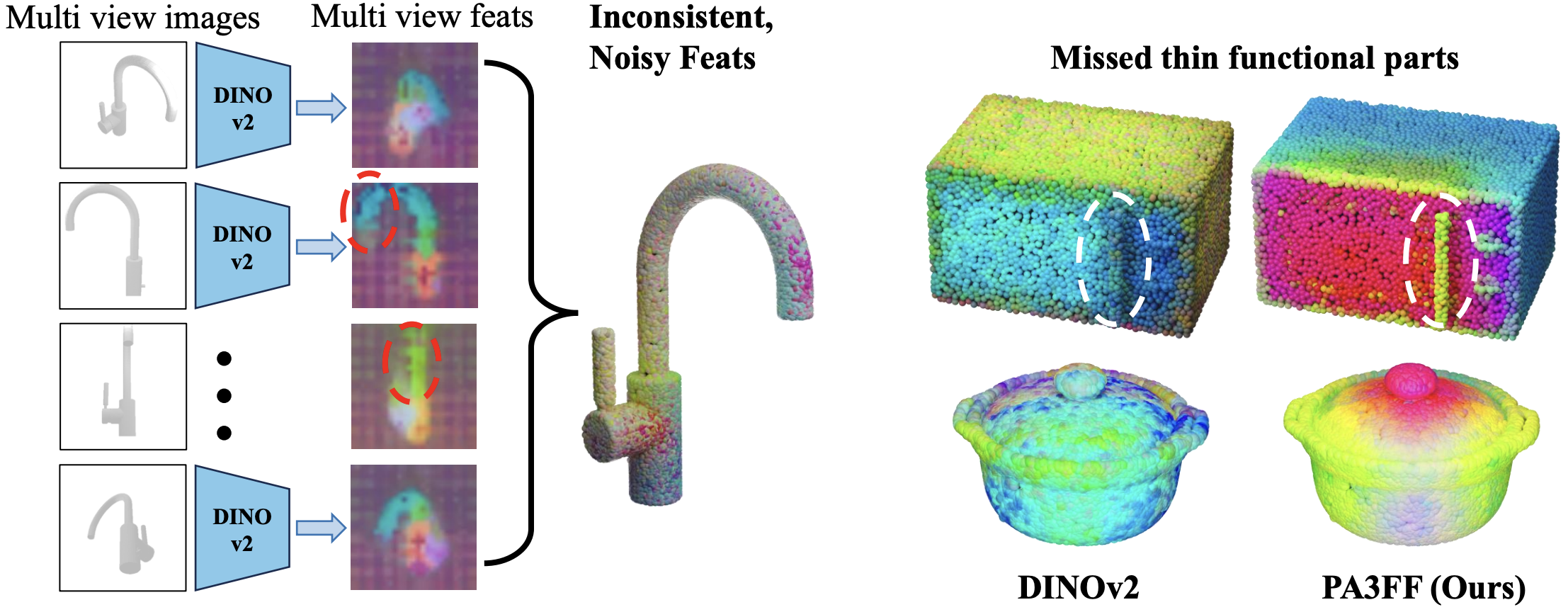
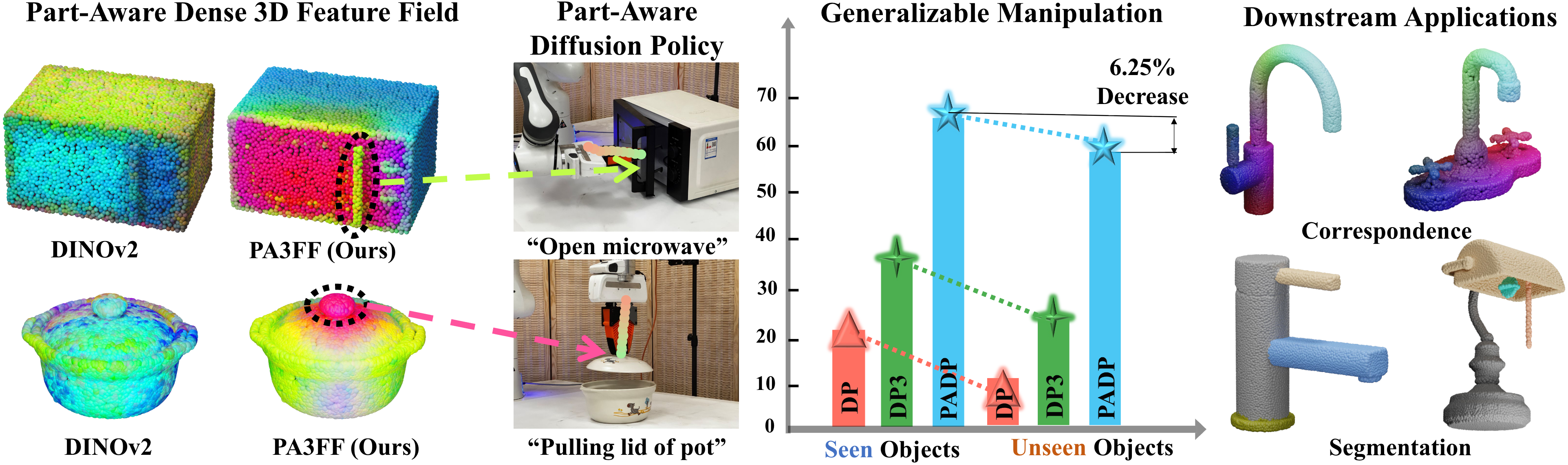
- • We introduce PA3FF, a 3D-native representation that encodes dense, semantic, and functional part-aware features directly from point clouds
- • We develop PADP, a diffusion policy that leverages PA3FF for generalizable manipulation with strong sample efficiency
- • PA3FF can further enable diverse downstream methods, including correspondence learning and segmentation, making it a versatile foundation for robotic manipulation
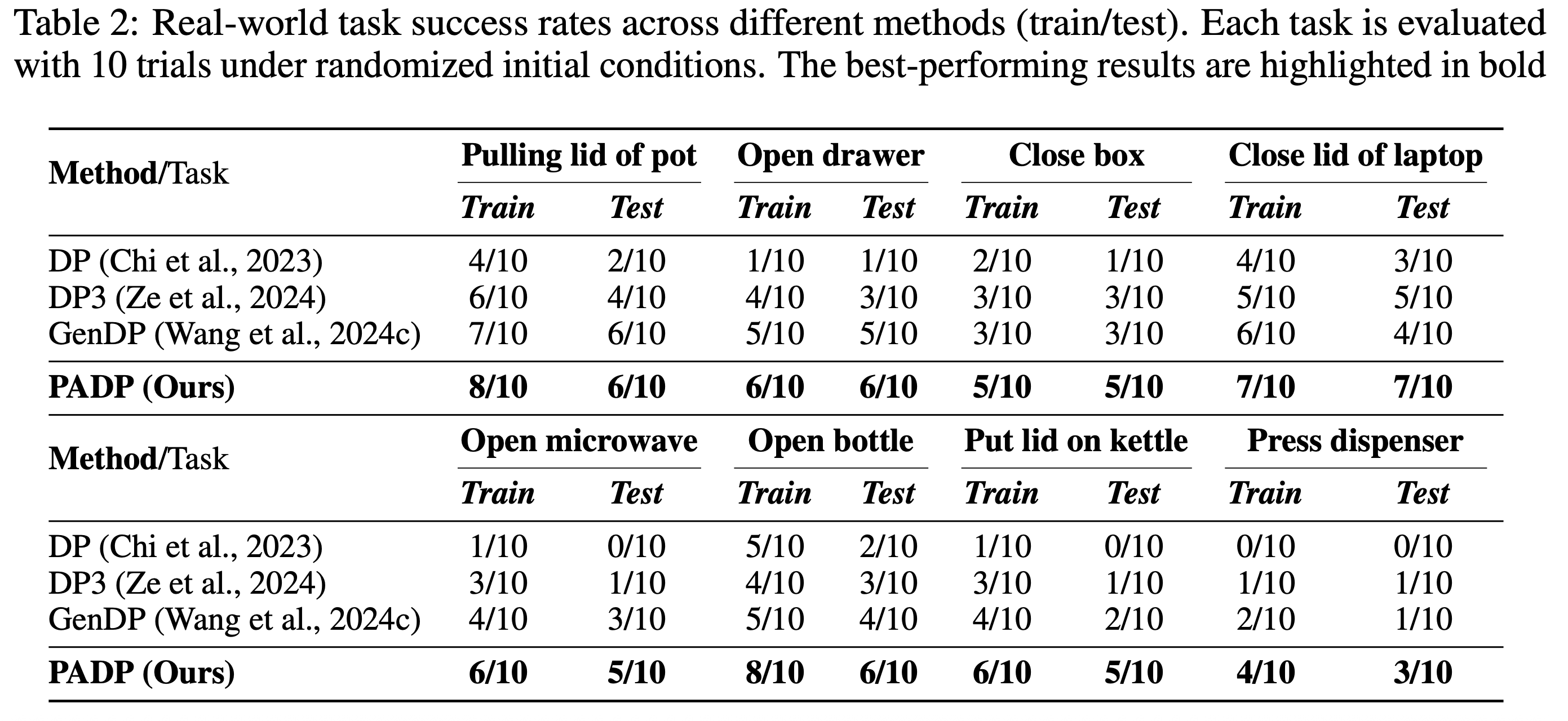
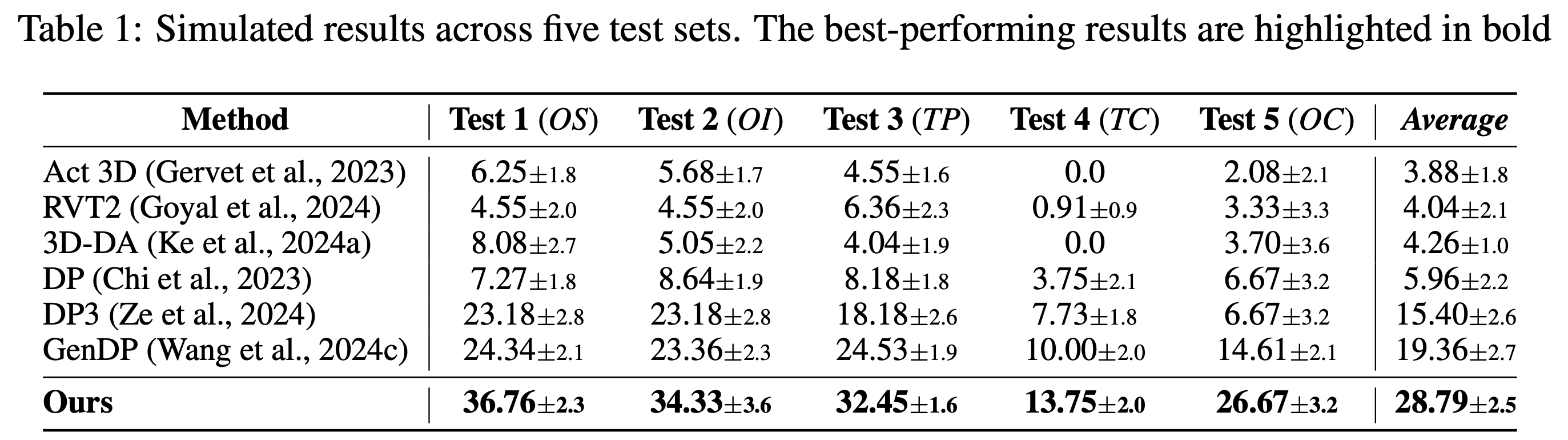
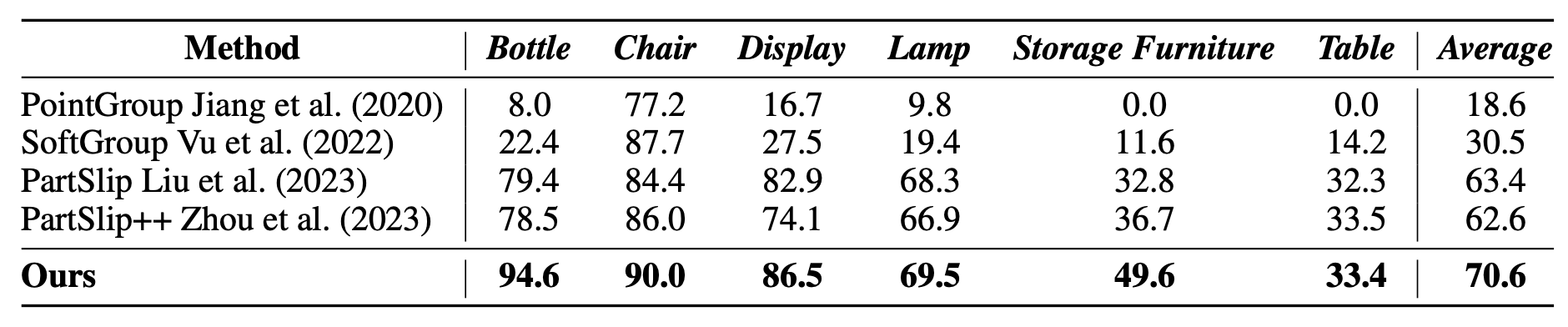
- • We validate our approach on 16 PartInstruct and 8 real-world tasks, where it significantly outperforms prior 2D and 3D representations (CLIP, DINOv2, and Grounded-SAM), offering a 15% and 16.5% increase