§ 02
Overview
A feedforward pipeline from point clouds to manipulation policy.
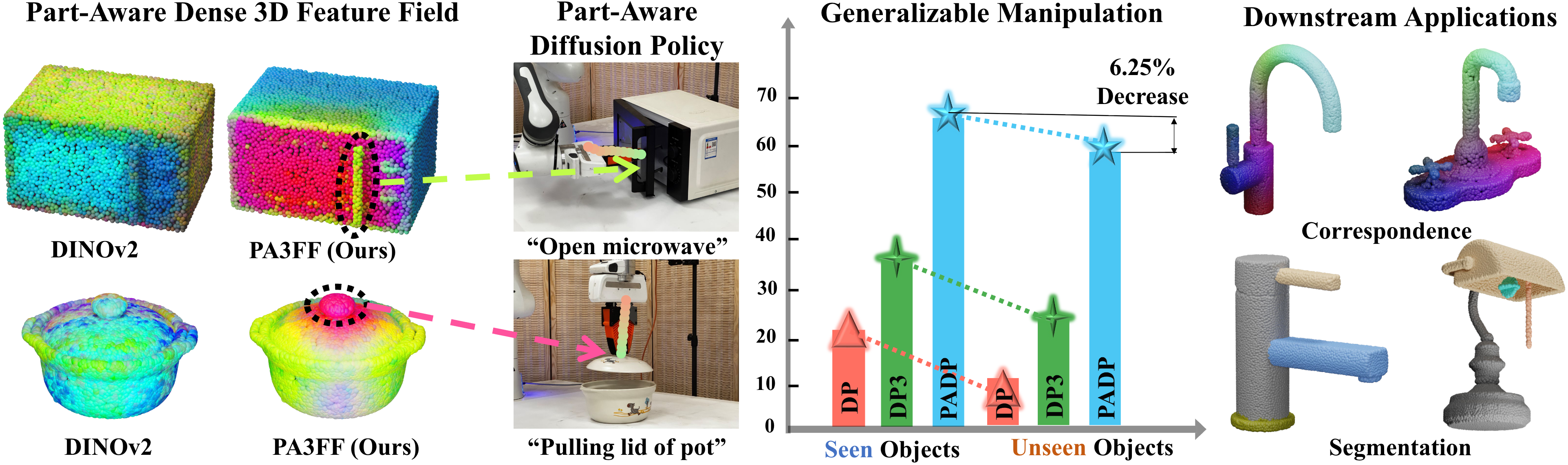
Figure 01
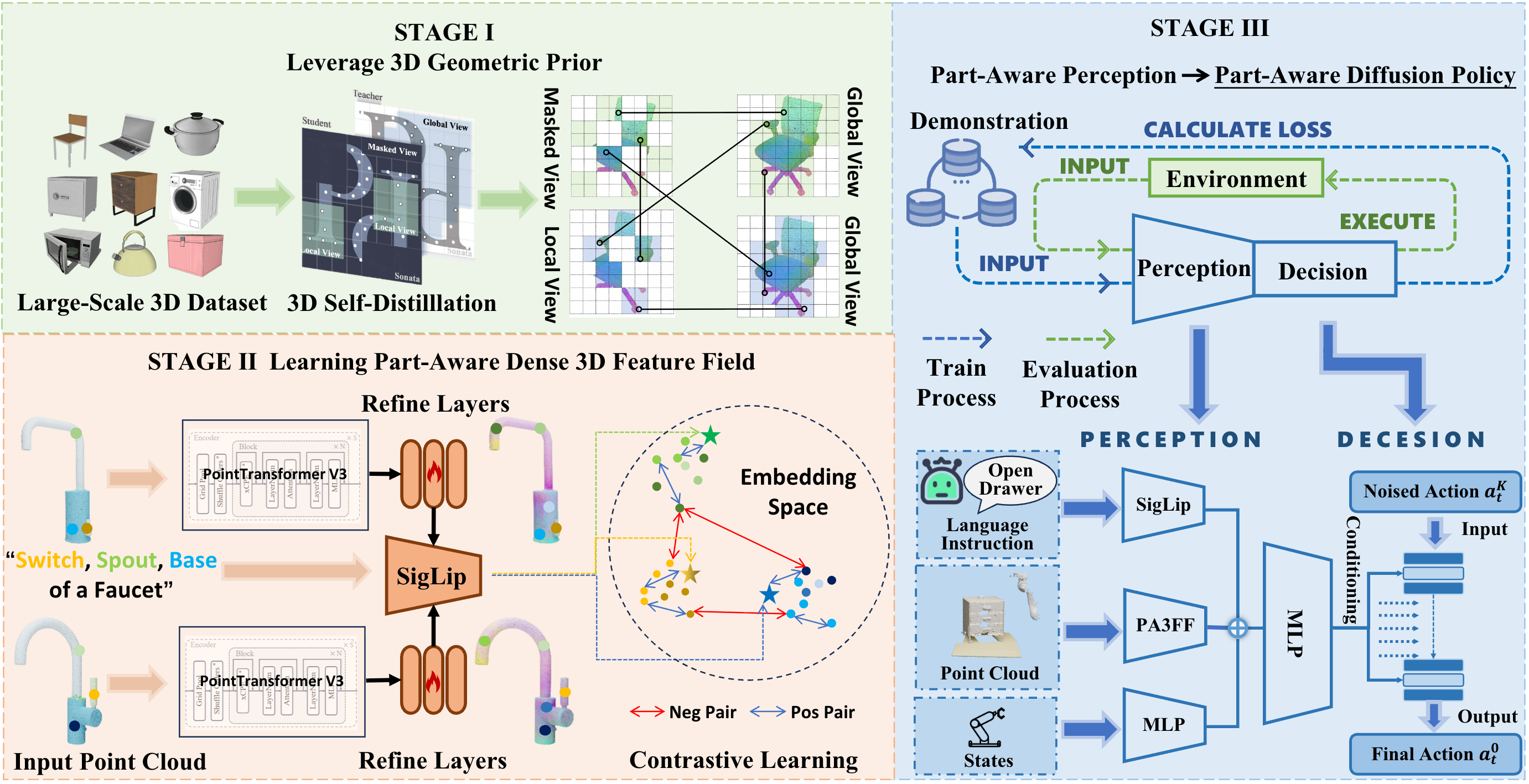
PA3FF Framework. We propose a feedforward model that predicts part-aware 3D feature fields, enabling generalizable manipulation across unseen objects. Our part-aware diffusion policy (PADP) achieves significant performance improvements with only 6.25% performance drop on unseen objects. PA3FF exhibits consistency across shapes, enabling downstream applications including correspondence learning and segmentation.
Four contributions.
- We introduce PA3FF, a 3D-native representation that encodes dense, semantic, and functional part-aware features directly from point clouds.
- We develop PADP, a diffusion policy that leverages PA3FF for generalizable manipulation with strong sample efficiency.
- PA3FF enables diverse downstream methods including correspondence learning and segmentation, making it a versatile foundation for robotic manipulation.
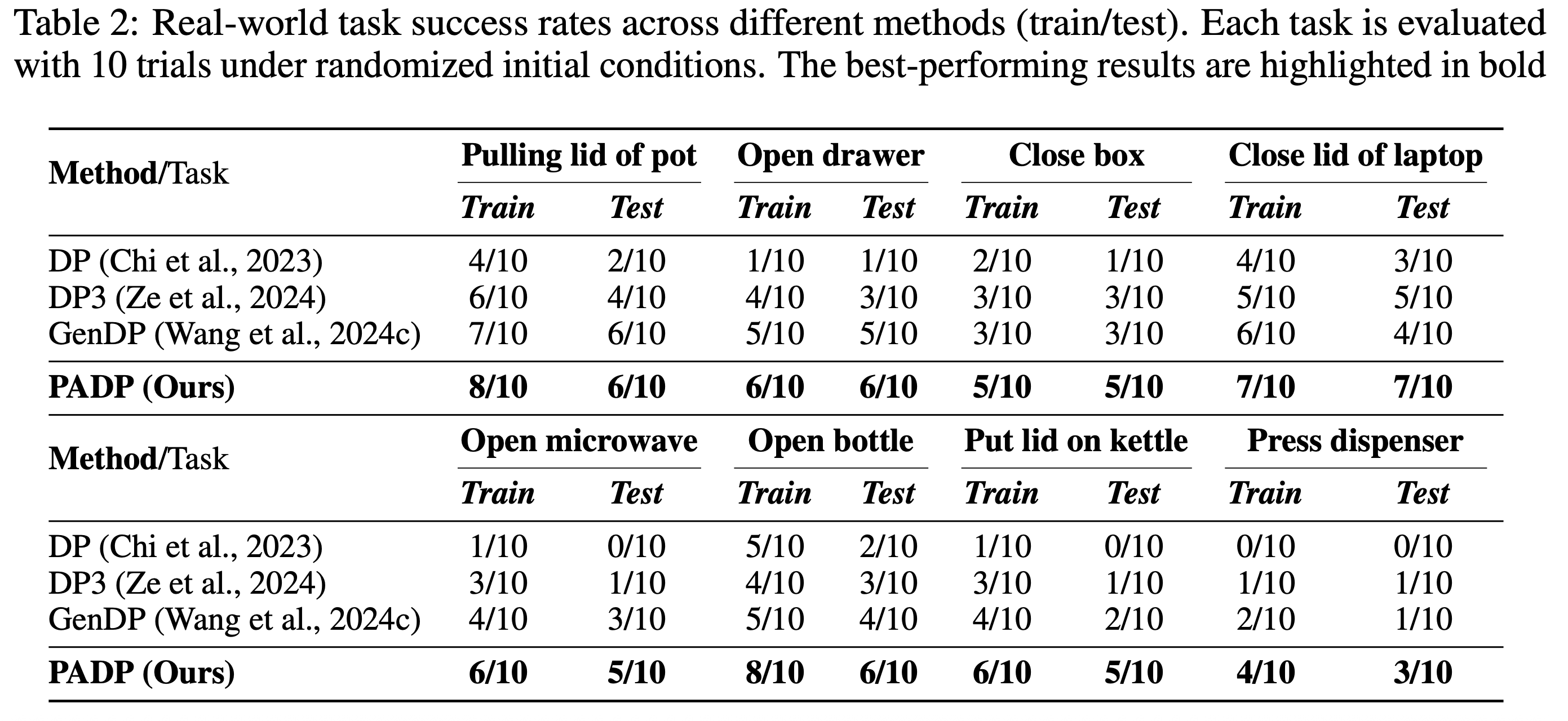
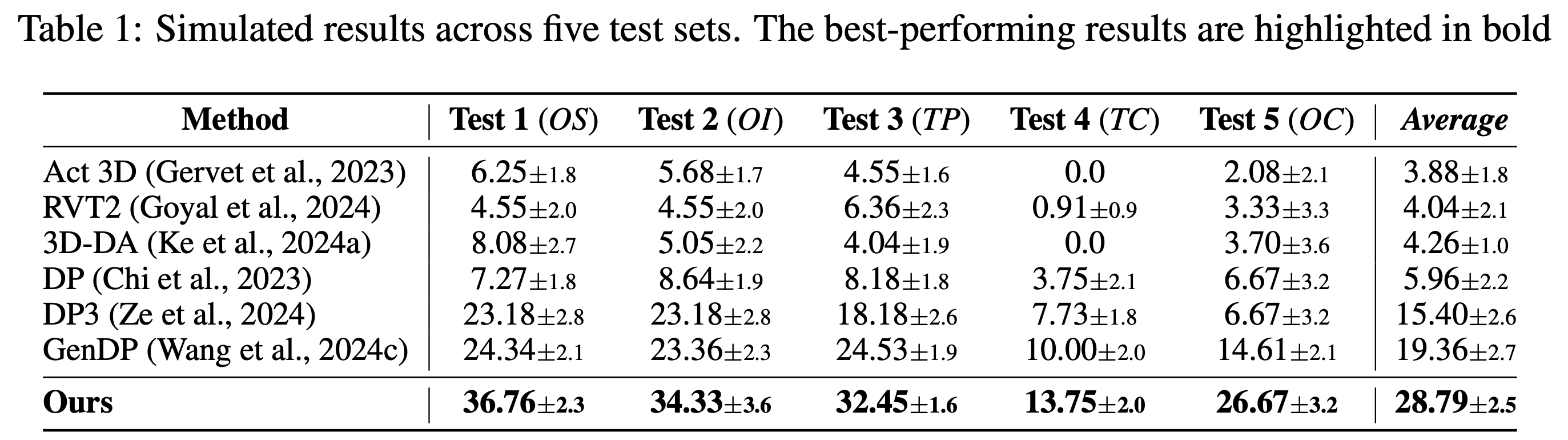
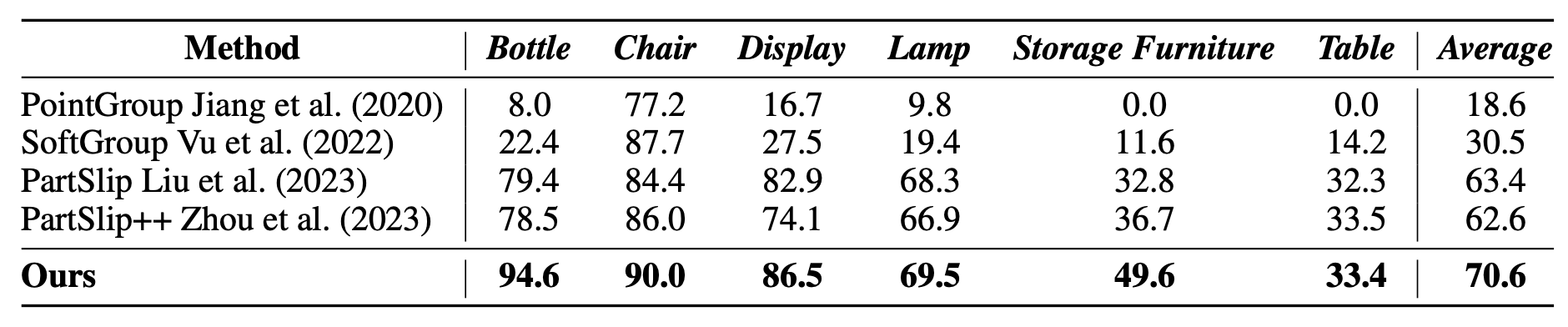
- We validate on 16 PartInstruct and 8 real-world tasks, outperforming prior 2D and 3D representations (CLIP, DINOv2, Grounded-SAM) by +15% and +16.5%.